Apple продовжує просувати індустрію ШІ вперед за допомогою більшої кількості моделей з відкритим кодом

Команда дослідників Apple Intelligence випустила два нові невеликі, але високопродуктивні мовні моделі, які використовуються для навчання генераторів штучного інтелекту.
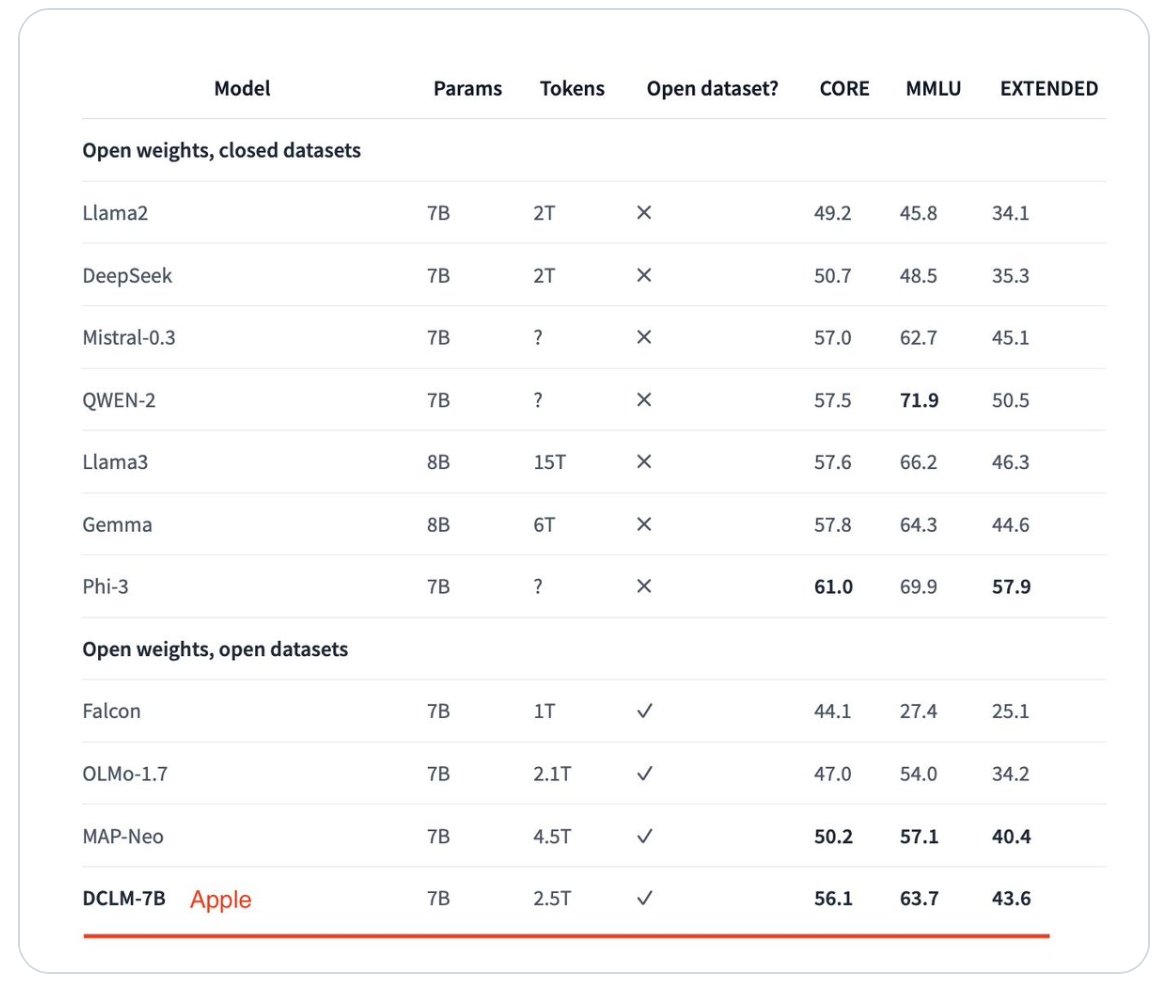
Команда машинного навчання Apple бере участь у проєкті з відкритим вихідним кодом DataComp для мовних моделей разом з іншими учасниками галузі. Дві моделі, які нещодавно створила Apple, демонструють відповідність або перевагу над іншими провідними моделями навчання, такими як Llama 3 та Gemma.
Такі мовні моделі використовуються для навчання двигунів штучного інтелекту, таких як ChatGPT, надаючи стандартну структуру. Це включає архітектуру, параметри та фільтрацію наборів даних для забезпечення вищої якості даних, з яких черпають двигуни штучного інтелекту.
Внесок Apple у проєкт включає дві моделі: більшу з семи мільярдами параметрів та меншу з 1,4 мільярда параметрів. Команда Apple зазначила, що більша модель перевершила попередню топову модель, MAP-Neo, на 6,6 відсотка у бенчмарках.
Що ще більш вражаюче, модель Apple DataComp-LM використовує на 40 відсотків менше обчислювальних ресурсів для досягнення цих бенчмарків. Це була найпродуктивніша модель серед тих з відкритими наборами даних, і конкурентоздатна проти моделей з приватними наборами даних.
Apple зробила свої моделі повністю відкритими — набір даних, вагові моделі та код тренувань доступні для інших дослідників. Як більші, так і менші моделі набрали достатньо балів у тестах Massive Multi-task Language Understanding (MMLU), щоб бути конкурентоспроможними проти комерційних моделей.
Представивши Apple Intelligence та Private Cloud Compute на конференції WWDC у червні, компанія спростувала критиків, які стверджували, що Apple відстає в галузі використання штучного інтелекту в своїх пристроях. Наукові статті від команди Machine Learning, опубліковані до і після цієї події, довели, що компанія є лідером у галузі штучного інтелекту.
Ці моделі, випущені командою Apple, не призначені для використання в майбутніх продуктах Apple. Вони є науково-дослідницькими проектами для демонстрації покращеної ефективності у створенні та використанні малих або великих наборів даних для тренування моделей штучного інтелекту.
Команда Machine Learning Apple раніше поділилася дослідженнями з ширшою спільнотою штучного інтелекту. Набори даних, наукові записи та інші матеріали можна знайти на HuggingFace.co, платформі, присвяченій розширенню спільноти штучного інтелекту.
Джерело: appleinsider.com
Як вам цей матеріал?